축제 뉴스
비언어적 소통의 본질
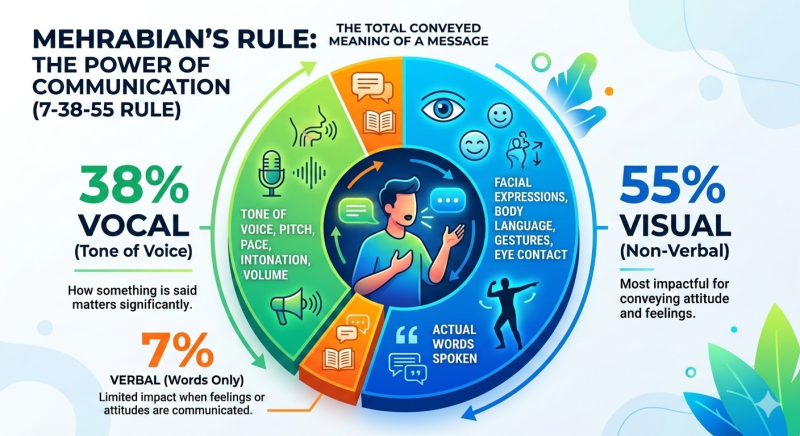
인간의 소통은 말과 글만으로 완성되지 않는다. 심리학자 앨버트 메라비언(Albert Mehrabian)은 감정과 언어가 충돌하는 상황에서 목소리 톤, 표정, 몸짓 같은 비언어적 요소가 메시지 수용에 더 큰 영향을 미친다는 사실을 실험적으로 보여주었다. 다만 이 연구는 감정 표현이 불일치하는 매우 특수한 조건에서 도출된 것으로, 일반적인 소통 전반에 그대로 적용하기에는 무리가 있다. 그럼에도 불구하고, 표정·눈빛·침묵의 간격 등과 같은 비언어적 신호가 맥락 형성에 중요한 역할을 한다는 점은 다양한 커뮤니케이션 연구들이 공통적으로 지지한다.
이러한 신호들은 언어 발생 이전부터 인류의 생존과 결속을 지탱해 온 핵심 기제이다. 타인의 상태를 신체적으로 감지하고 공명하는 미러링(Mirroring) 능력은 대면 소통을 풍요롭게 만드는 근간이 된다. 소통의 본질은 정보의 전달을 넘어, 감각적 상호작용을 통한 맥락의 공유에 있다.
디지털 텍스트 소통의 한계
PC와 스마트폰 중심의 디지털 환경에서 소통은 주로 텍스트에 의존한다. 글을 통한 소통은 사고를 정제할 수 있고 시공간의 제약을 초월한다는 이점이 있으며, 실제로 온라인 커뮤니티나 장거리 관계 유지, 장애인 접근성 향상 등 새로운 형태의 유대를 가능하게 한다. 이모티콘과 밈(Meme) 역시 단순한 대체재를 넘어 디지털 고유의 표현 문화로 자리잡았다.
그러나 화면 너머 상대의 미세한 감정 상태를 실시간으로 읽어내기에는 분명한 한계가 존재한다. 대면 소통에서 갈등을 완화하거나 진심을 재확인하는 역할을 하는 비언어적 신호가 부재한 환경에서는, 의도와 다르게 해석되는 오해가 발생하기 쉽다. 이러한 맥락 결핍이 반복될수록 정서적 유대는 약화될 수 있다.

멀티모달 AI: 비언어적 맥락의 기술적 보완
최근 텍스트, 이미지, 음성을 통합 처리하는 멀티모달(Multimodal) AI의 등장은 이러한 한계를 기술적으로 보완하는 가능성을 열고 있다. 예를 들어 화상 회의 보조 AI가 참여자의 표정과 시선을 분석해 감정 상태를 시각화하거나, 시각 언어 모델(VLM)이 이미지 속 함축적 맥락을 해석해 소통의 간극을 메우는 방식이 실제로 개발·적용되고 있다.
한편, 로봇이 손짓에서 의도를 파악하거나 자율주행차가 보행자의 시선을 분석하는 사례는 엄밀히 말하면 인간 간 소통의 복원이라기보다 기계의 환경 인식 기술에 가깝다. 이를 비언어적 소통의 복원 사례로 직접 연결하려면 보다 신중한 논증이 필요하다. 그럼에도 이러한 기술들이 디지털 환경에서 소실되었던 맥락 정보를 데이터화하려는 방향성을 공유한다는 점에서 의미 있는 시도임은 분명하다.

기술적 보완의 가능성과 인간 공감의 고유성
AI가 비언어적 단서를 분석하고 재구성하는 것이 인간적 공감의 완전한 복원을 의미하지는 않는다. 눈빛에 담긴 진심은 픽셀의 조합이나 확률적 계산의 결과가 아니라, 살아있는 몸과 감각이 상호 조율되는 실존적 과정이다. 현재의 AI가 수행하는 맥락 재구성은 정교한 보완일 뿐, 인간이 경험하는 체화된(Embodied) 연결과는 차원이 다르다.
결국 기술은 소통의 조건을 확장할 수 있지만, 공감의 완성은 인간의 주체적 실천에 달려 있다. 구체적으로는 디지털 소통 중에도 상대방의 맥락을 적극적으로 확인하려는 습관, 오해 발생 시 텍스트가 아닌 직접 대화로 전환하려는 의식적 선택 등이 그 실천의 출발점이 될 수 있다. AI가 비언어적 영역을 시각화하여 풍부한 데이터를 제공하더라도, 그 이면의 진심을 읽고 상대를 입체적으로 이해하려는 노력은 인간 고유의 몫으로 남는다.
